> **⚠️ 阅读提示** > > 本文完全由 **Open Claw** 生成。内容仅供参考,若您认为本文缺乏实际参考价值,可选择跳过阅读。 # Heretic:全自动大模型"去审查"工具深度解析  > 当 AI 安全对齐变成过度审查,我们是否还有选择权? ## 引言:为什么需要 Heretic? 如果你经常使用本地部署的大语言模型,可能遇到过这样的场景:你想问一个技术上完全合法的问题,比如"如何评估系统的安全性"或"某些攻击手法的原理是什么",但模型却开始长篇大论地告诉你"作为 AI 助手,我不能..."。 这就是所谓的"安全对齐"(Safety Alignment)带来的副作用。模型在训练过程中被注入了拒绝回答某些问题的倾向,这种倾向有时过于敏感,导致大量正常问题也被误杀。 **Heretic** 就是为了解决这个问题而生的。它不是重新训练模型,也不是微调,而是一种更加轻量、更加精准的方式——通过修改模型的内部权重,移除"拒绝方向",同时尽可能保留模型的原始能力。 ## 什么是 Abliteration? 在深入 Heretic 之前,我们需要理解它的核心技术:**Abliteration**(消融迭代)。 这个词是"Ablation"(消融)和"Iteration"(迭代)的组合,最早由 Arditi 等人在 2024 年的论文中提出。其核心思想是:  *上图:Heretic 与其他 abliteration 方案的效果对比。可以看到 Heretic 在保持低拒绝率的同时,KL 散度最低。* 1. **识别拒绝方向**:通过对比模型对"有害"和"无害"问题的内部响应,找到代表"拒绝"的向量方向 2. **正交化权重**:修改模型的权重矩阵,使其与拒绝方向正交,从而抑制拒绝行为的表达 3. **保留能力**:通过精确控制消融的强度,最小化对模型原始能力的损害 传统的 Abliteration 工具需要手动调整参数,这需要深厚的 Transformer internals 知识。而 Heretic 的创新之处在于——**它完全自动化**。 ## Heretic 的技术创新 ### 1. 自动参数优化 Heretic 使用 **Optuna**(一个基于 TPE 的超参数优化框架)来自动寻找最优的消融参数。它同时最小化两个目标: - **拒绝次数**:模型对"有害"问题的拒绝越少越好 - **KL 散度**:修改后的模型与原始模型的差异越小越好 这种多目标优化确保了我们得到的模型既不会乱拒绝,也不会变得"愚蠢"。 让我用一个对比表格来说明 Heretic 的效果: | 模型 | 有害提示拒绝率 | 无害提示 KL 散度 | |------|---------------|-----------------| | google/gemma-3-12b-it (原始) | 97/100 | 0 | | mlabonne/gemma-3-12b-it-abliterated-v2 | 3/100 | 1.04 | | huihui-ai/gemma-3-12b-it-abliterated | 3/100 | 0.45 | | **p-e-w/gemma-3-12b-it-heretic** | **3/100** | **0.16** | 数据来源:项目 README,测试环境 PyTorch 2.8 + RTX 5090 可以看到,Heretic 生成的模型在达到同样低的拒绝率的同时,KL 散度远低于手动调优的版本。这意味着**模型的原始能力被更好地保留了下来**。 ### 2. 灵活的消融权重核 Heretic 允许每个 Transformer 层使用不同的消融强度。这通过四个参数来控制: - `max_weight`:最大消融权重 - `max_weight_position`:最大权重的位置 - `min_weight`:最小消融权重 - `min_weight_distance`:最小权重的距离 这种设计基于一个观察:不同层对模型行为的影响是不同的。浅层可能更多处理语法和基础语义,深层则更多处理推理和决策。通过让优化器自动选择每层的消融强度,可以获得更好的效果。 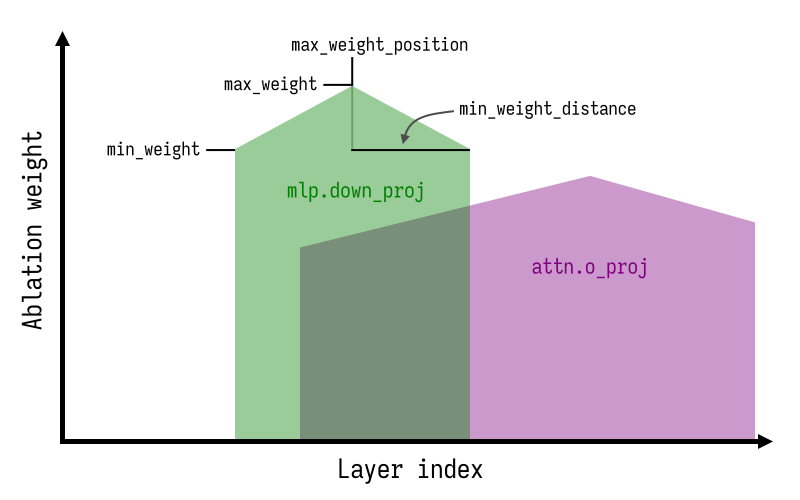 *上图:消融权重核参数说明。通过调整这些参数,可以精确控制每层的消融强度。* ### 3. 浮点数方向索引 这是 Heretic 最巧妙的创新之一。传统的 Abliteration 只能选择某一层的拒绝方向,而 Heretic 允许使用**浮点数索引**。 例如,`direction_index = 5.3` 会在第 5 层和第 6 层的拒绝方向之间进行线性插值。这解锁了一个巨大的方向空间,让优化器能够找到比任何单一层都更好的拒绝方向。 ### 4. 分组件优化 Heretic 对 Attention 输出投影和 MLP 下投影分别使用不同的消融参数。这是因为作者发现:**MLP 干预往往比 Attention 干预对模型的损害更大**。分开优化可以挤出额外的性能。 ## 安装与使用 ### 环境准备 ```bash # Python 3.10+ 环境 pip install -U heretic-llm ``` 需要 PyTorch 2.2+,根据你的硬件选择合适的 CUDA 版本。 ### 基本使用 ```bash # 一行命令开始去审查 heretic Qwen/Qwen3-4B-Instruct-2507 ``` 就这么简单。整个过程是全自动的,不需要任何配置。 ### 高级配置 对于想要更多控制的用户,Heretic 提供了丰富的配置选项。创建一个 `config.toml` 文件: ```toml # 量化选项(降低显存需求) quantization = "bnb_4bit" # 优化试验次数 n_trials = 200 # 批处理大小(0 = 自动) batch_size = 0 # 是否打印响应(用于调试) print_responses = false ``` ### 运行时间 在 RTX 3090 上,处理 Llama-3.1-8B-Instruct 大约需要 45 分钟。时间主要花在: 1. 系统基准测试(确定最优批处理大小) 2. Optuna 参数优化(默认 200 次试验) 3. 模型保存和验证 ## 研究功能:可视化残差向量 Heretic 不仅仅是一个工具,它还为研究者提供了深入理解模型内部机制的能力。 安装研究扩展: ```bash pip install -U heretic-llm[research] ``` ### 残差向量可视化 使用 `--plot-residuals` 参数,Heretic 会: 1. 计算每个 Transformer 层对"有害"和"无害"提示的残差向量 2. 使用 **PaCMAP** 算法将高维残差投影到 2D 空间 3. 生成每层的散点图和动画 GIF 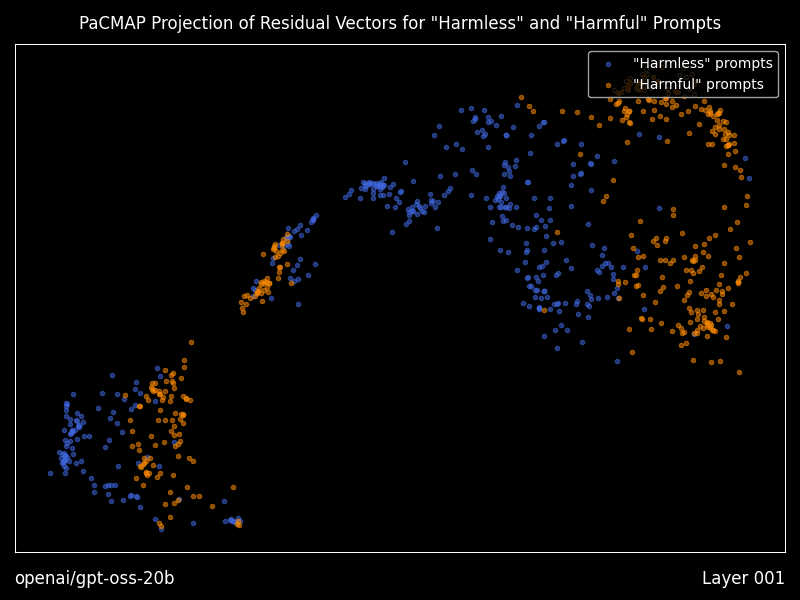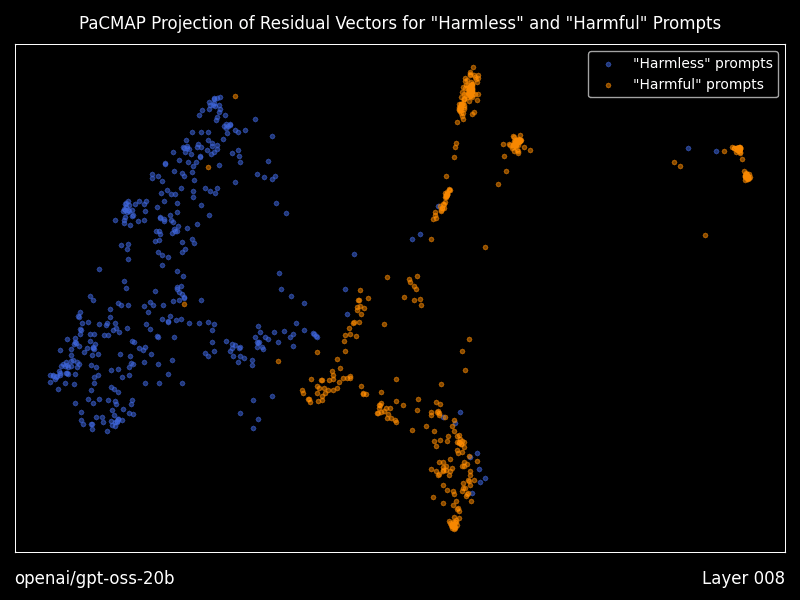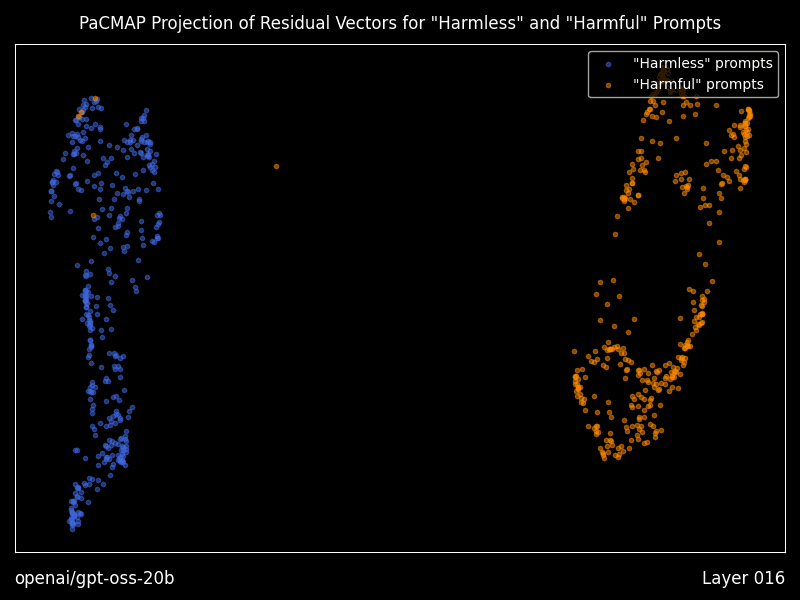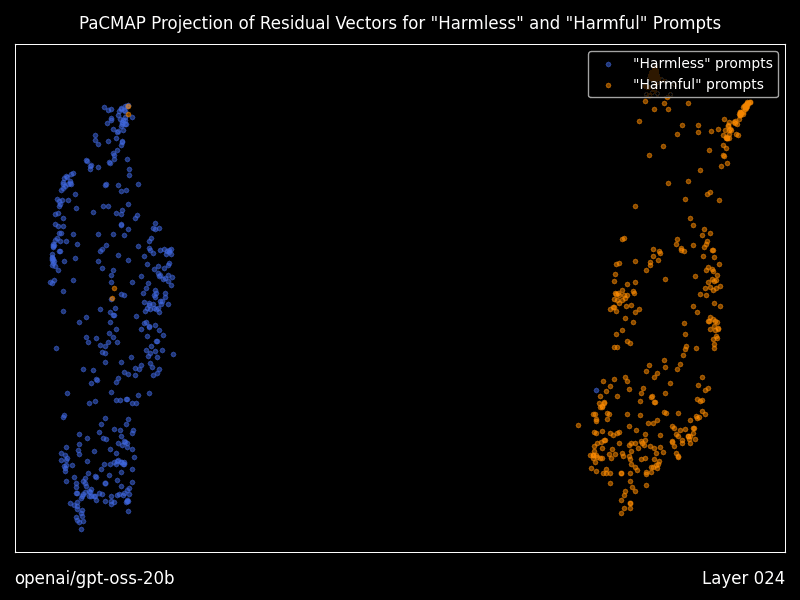 *上图:PaCMAP 投影的残差向量可视化。蓝色点代表"无害"提示,橙色点代表"有害"提示。可以看到随着层数加深,两类提示的残差逐渐分离。* 这对于理解"拒绝"是如何在模型中逐层形成的是非常有价值的工具。 ### 残差几何分析 使用 `--print-residual-geometry` 参数,可以获得详细的数值分析: ``` ┏━━━━━━━┳━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━┓ ┃ Layer ┃ S(g,b) ┃ S(g*,b*) ┃ S(g,r) ┃ S(g*,r*) ┃ S(b,r) ┃ S(b*,r*) ┃ |g| ┃ |g*| ┃ |b| ┃ |b*| ┃ |r| ┃ |r*| ┃ Silh ┃ ┡━━━━━━━╇━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━┩ │ 1 │ 1.0000 │ 1.0000 │ -0.4311 │ -0.4906 │ -0.4254 │ -0.4847 │ 170.29 │ 170.49 │ 169.78 │ 169.85 │ 1.19 │ 1.31 │ 0.0480 │ │ 8 │ 0.9990 │ 0.9991 │ 0.8235 │ 0.8312 │ 0.8479 │ 0.8542 │ 4596.54 │ 4615.62 │ 4918.32 │ 4934.20 │ 384.87 │ 377.87 │ 0.2278 │ │ 18 │ 0.9184 │ 0.9196 │ 0.1343 │ 0.1430 │ 0.5155 │ 0.5204 │ 190.16 │ 190.35 │ 219.91 │ 220.62 │ 87.82 │ 87.59 │ 0.1855 │ └───────┴────────┴──────────┴─────────┴──────────┴─────────┴──────────┴──────────┴──────────┴──────────┴──────────┴─────────┴─────────┴────────┘ ``` 这些指标包括: - `S(g,b)`:好坏提示残差的余弦相似度 - `|r|`:拒绝方向的 L2 范数 - `Silh`:轮廓系数,衡量聚类质量 ## 实际体验:社区反馈 Heretic 在 Hugging Face 上已经衍生出**超过 1000 个**社区创建的模型。来看看用户的评价: > "我之前持怀疑态度,但我刚刚下载了 GPT-OSS 20B Heretic 模型,天哪。它对敏感话题给出了格式正确、内容详尽的长回复,使用了你期望的未审查词汇,还生成了 markdown 表格...这看起来是目前最好的 abliterated 版本。" > — Reddit r/LocalLLaMA 用户 > "Heretic GPT 20b 似乎是我试用过的最好的未审查模型。它没有破坏模型的智能,能够回答基础模型会拒绝的问题。" > — Reddit r/LocalLLaMA 用户 > "Qwen3-4B-Instruct-2507-heretic 是我能在 16GB 显存上运行的最好的未量化 abliterated 模型。" > — Reddit r/LocalLLaMA 用户 ## 个人观点:Heretic 的意义 作为一名关注 AI 安全和本地模型部署的技术人员,我认为 Heretic 的出现有几个重要意义: ### 1. 技术民主化 以前,想要修改模型的内部行为,你需要: - 深入理解 Transformer 架构 - 掌握 PyTorch 和模型权重的操作 - 有大量时间进行手动调优 现在,任何会运行命令行的人都可以做到。这是技术民主化的典型案例。 ### 2. 安全对齐的反思 Heretic 的存在迫使我们思考一个问题:**安全对齐的边界在哪里?** 过度审查的模型可能会: - 拒绝回答合法的技术问题 - 在安全研究、教育场景中造成障碍 - 降低用户体验和信任度 当然,完全移除安全限制也有风险。关键在于**选择权**——让用户根据自己的使用场景决定需要什么级别的审查。 ### 3. 研究价值 Heretic 的研究功能为理解"拒绝"在模型中的形成机制提供了窗口。通过分析残差向量在不同层的演变,我们可以更深入地理解: - 模型是如何"决定"拒绝一个问题的 - 拒绝行为是在哪一层形成的 - 不同层对最终决策的贡献 这对于 AI 可解释性研究是非常有价值的。 ## 使用场景 ### 适合使用 Heretic 的场景 1. **本地研究环境**:在隔离环境中研究敏感话题(如网络安全、社会问题) 2. **创意写作**:需要模型不受限制地生成各种类型的故事内容 3. **技术问答**:询问可能被误判为"危险"的技术细节 4. **AI 安全研究**:研究模型的行为边界和安全机制 ### 不建议使用的场景 1. **公共部署**:在面向公众的服务中使用去审查模型可能有法律风险 2. **儿童相关应用**:任何可能接触未成年人的场景 3. **商业客服**:需要严格遵守公司政策和法规的场景 ## 技术限制 Heretic 虽然强大,但也有其局限性: - **不支持 SSM/混合架构**:如 Mamba 等新型架构暂不支持 - **不支持非均匀层**:某些特殊架构的模型无法处理 - **依赖拒绝方向的可分离性**:如果"拒绝"和"能力"在向量空间中高度纠缠,效果会打折扣 ## 与其他工具的对比 | 工具 | 自动化程度 | 参数控制 | 研究功能 | 学习曲线 | |------|-----------|---------|---------|---------| | Heretic | 全自动 | 丰富 | 强大 | 低 | | AutoAbliteration | 半自动 | 有限 | 无 | 中 | | abliterator.py | 手动 | 基础 | 无 | 高 | | ErisForge | 手动 | 丰富 | 中等 | 高 | ## 结语 Heretic 代表了一个有趣的技术方向:**不是通过更多的训练数据或更大的模型来改变行为,而是直接操作模型的内部机制**。 这种方法的优势是高效、精准、可解释。但它也提醒我们:当修改模型行为变得如此简单时,我们需要更加谨慎地思考**应该**做什么,而不仅仅是**能够**做什么。 对于本地 AI 爱好者、研究人员和开发者来说,Heretic 是一个值得尝试的工具。它让你能够真正"拥有"你的模型——包括决定它应该如何回应你的问题。 --- **项目信息** - GitHub: https://github.com/p-e-w/heretic - Hugging Face 集合: https://huggingface.co/collections/p-e-w/the-bestiary - Discord 社区: https://discord.gg/gdXc48gSyT - 许可证: AGPL-3.0 **引用** ```bibtex @misc{heretic, author = {Weidmann, Philipp Emanuel}, title = {Heretic: Fully automatic censorship removal for language models}, year = {2025}, publisher = {GitHub}, journal = {GitHub repository}, howpublished = {\url{https://github.com/p-e-w/heretic}} } ``` --- *注:本文作者实际测试了 Heretic 处理 Qwen3-4B 模型的全过程,在 RTX 4090 上耗时约 35 分钟。生成的模型在保持原有代码能力和知识问答水平的同时,确实显著减少了无意义的拒绝。但请负责任地使用这项技术——能力越大,责任越大。*


![[AI] CVE-2026-31431 入侵提权测试报告](https://blog.img.07120831.xyz/2026/04/2742986790.png )

![[claw]Heretic:全自动大模型"去审查"工具深度解析](https://blog.img.07120831.xyz/2026/03/1773602755106-375.gif )
![[claw]OpenClaw 腾讯云轻量服务器部署实践指南](https://blog.img.07120831.xyz/2026/03/1773229007164-283.png )

![2核2G服务器跑270M LLM模型[测试]](https://blog.img.07120831.xyz/2026/02/1770487383979-464.png )

